DolphinScheduler 解锁数据处理与交易业务中错综复杂的依赖关系
在当今数据驱动的商业环境中,无论是支撑实时决策的在线数据处理(OLAP),还是保障业务连续性与一致性的在线交易处理(OLTP),其背后往往涉及一系列步骤繁多、逻辑交错的数据处理流程。这些流程中的任务之间存在着复杂的依赖关系,一个环节的延迟或失败可能引发连锁反应,严重影响业务的时效性与可靠性。此时,一个强大、可靠的工作流调度引擎便成为技术架构中的关键枢纽。Apache DolphinScheduler,作为一款开源的分布式可视化工作流任务调度平台,正致力于高效、优雅地解决这一核心挑战。
一、直面核心挑战:错综复杂的依赖关系
在数据处理与交易业务场景中,依赖关系通常呈现多维形态:
- 时间依赖:任务需要在特定时间点或周期(如每日凌晨)触发。
- 数据依赖:下游任务必须等待上游任务成功产出特定数据文件或数据库表后才能执行。
- 资源依赖:任务执行需要特定的计算资源(如CPU密集型、内存密集型)或环境就绪。
- 逻辑依赖:基于上游任务的执行状态(成功、失败)或输出结果,动态决定下游任务的执行路径(分支、条件判断)。
传统使用Crontab加脚本的方式,在应对这些复杂、动态的依赖时,往往显得力不从心,导致运维成本高昂、故障排查困难、任务编排僵化。DolphinScheduler通过其核心设计,为这些痛点提供了系统化的解决方案。
二、DolphinScheduler的破局之道
DolphinScheduler以“可视化、高可靠、高可扩展”为设计原则,为复杂工作流管理提供了强大支撑:
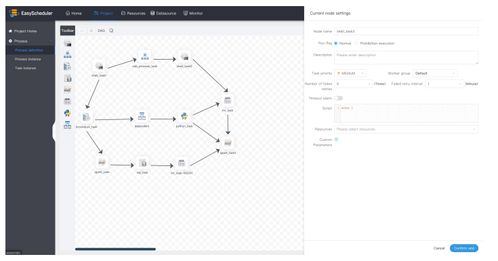
- 可视化DAG编排:用户可以通过直观的拖拽界面,以有向无环图(DAG)的方式定义任务节点及依赖关系。这极大地降低了编排复杂度,使依赖关系一目了然,便于管理和维护。无论是简单的线性流程,还是包含分支、条件判断、循环的复杂流程,都能轻松建模。
- 分布式与高可用架构:采用Master-Worker的分布式架构,Master负责任务的调度与监控,Worker负责任务的执行。服务支持多主多从,避免了单点故障,确保了调度引擎自身在面对大规模、高并发任务流时的稳定性和可靠性,这对于7x24小时不间断的交易处理业务至关重要。
- 精细化的任务与依赖控制:
- 多类型任务支持:原生支持Shell、SQL、Spark、Flink、Python、HTTP等数十种任务类型,能无缝融入数据处理技术栈。
- 灵活的依赖定义:不仅支持任务间的直接依赖,还支持跨工作流、跨项目的依赖,并能基于文件、条件状态等多种参数触发,精准刻画现实业务逻辑。
- 优先级与故障转移:支持任务优先级设置和容错重试机制,当任务失败时,可自动或手动重试、告警,并支持设定失败后的处理策略(如继续、暂停、终止流程),保障关键路径的顺利执行。
- 完善的监控与告警:提供任务执行状态、日志、运行时长等全方位监控视图。与邮件、钉钉、企业微信等通知渠道集成,能实时将任务成功、失败、超时等信息推送给负责人,助力快速响应与故障恢复。
三、赋能在线数据处理与交易处理业务
在具体的业务场景中,DolphinScheduler的价值得以充分体现:
- 在OLAP(在线数据分析)场景:一个典型的每日报表分析流程,可能涉及数据抽取(从多个OLTP库)、清洗转换、多维建模、指标计算、报表生成等多个步骤。DolphinScheduler可以编排这个复杂的DAG,确保每一步都严格依赖前一步的数据产出,并在每天指定时间自动启动,最终将新鲜的数据报表准时呈现给决策者。
- 在OLTP(在线交易处理)场景:虽然核心交易链路通常由业务系统直接处理,但其周边支撑的数据流程,如交易数据的实时归档、对账文件生成、风控指标计算、日终批量清算等,同样依赖关系复杂且对时效和准确性要求极高。DolphinScheduler能够可靠地调度这些批处理或准实时任务,确保它们在不干扰核心交易的前提下,有序、准确地完成,保障业务的财务合规与运营安全。
四、
总而言之,Apache DolphinScheduler通过其可视化的编排能力、分布式的可靠架构以及对复杂依赖关系的精细化控制,成功地将数据工程师和运维人员从繁琐、易错的任务调度管理中解放出来。它不仅是自动化任务的“执行者”,更是理顺业务流程逻辑、保障数据处理与交易业务平稳高效运行的“规划师”与“守护者”。随着企业数据流程日益复杂,DolphinScheduler这样的现代化调度引擎,正成为构建稳健、敏捷数据基础设施不可或缺的一环。
如若转载,请注明出处:http://www.xfyaaa.com/product/40.html
更新时间:2026-06-18 20:12:09